















005:フラットLoRAについて
月須和・那々さん(twitter @nana_tsukisuwa)のtest-flat
https://huggingface.co/2vXpSwA7/iroiro-lora/tree/main/sdxl
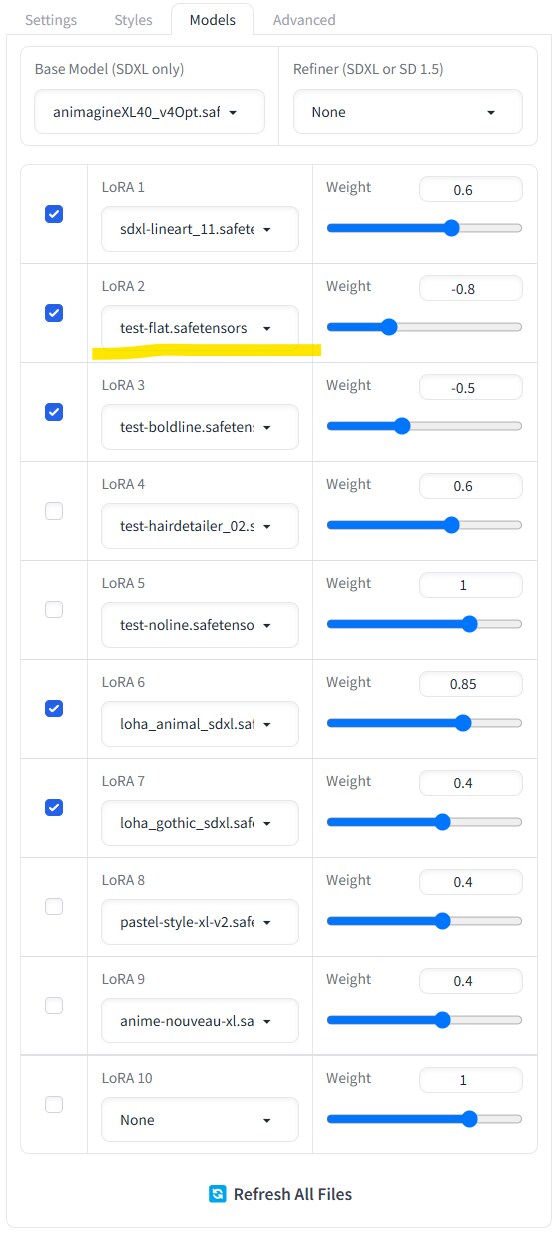
2枚目:Fooocusだと「Models」タブからLoRAを複数指定できるので、そこで指定しています。
今回はSEED値とプロンプトを固定で、LoRAの重みを変えて出力し、フラットLoRAがどういった効果を持つのかをお見せしようかなと。
月須和・那々さんのLoRAは癖が少なくて、たいへん便利なので他のLoRAも試してみると良いと思います。
フラットLoRAは重みに応じて、絵柄が単純で平坦なものになります。
アイコンに使うような、シンプルな絵柄を出力したいときに便利です。
3枚目:重み2.0
4枚目:重み1.0
5枚目:重み0.5
6枚目:重み0.0
ただ、私がこのフラットLoRAを使うときはマイナスの重みをつけることが多いです。
マイナスの重みで使用すると、絵柄が複雑で細部まで描き込まれたものになります。
7枚目:重み-0.5
8枚目:重み-1.0
9枚目:重み-2.0
==========
ちなみにサンプル画像のプロンプトは以下の通りです。今回は描き込みの変化が分かりやすいかな、ということでスチームパンク風(steampunk style)を指定してみました。
1girl, _ , from _ , pale pink blonde hair, very short hair, long sidelocks, hair between eyes, red eyes, round glasses, pointy ears, large breast, high neck no sleeve steampunk style leather jacket, Gear ornament, beret, short red skirt, pleated skirt, contrapposto, Complex machinery, lots of gears, lots of joints, steampunk style background, thick fog around, BREAK masterpiece, best quality, high score, great score, ultra-detailed high resolution (anime-style 3dcg:1.0), intricate details light color, whitish color line art, light diffusion, muted color, Matte flat color, watercolor gradiation, hyper-realistic, Sleek design

 6
6
036:Qwen Image Edit の使い方
全体公開
今回は、元画像からテキスト指示で画像を編集できるQwen Image Editを試してみました。 例によって、差分の画像をStart-Endにフレーム指定して動画を作るのに便利、という動機からです。 まずは元画像としていつものようにAnim4gineで画像を用意します(2枚目)。 これを3枚目の画像のようにしてQwen Image Editのワークフローにセットします。 プロンプトとしては、「背景だけをフォトリアルな森の画像に差し替えてください」みたいな自然文をgoogle翻訳で英語にしたものを使ってみました(4枚目)。 今度は4枚目の画像を元にして、「キャラクターを削除して背景だけにしてください」とすると、5枚目のような森の風景だけの画像になりました。消しゴムマジックみたいなことができますね。 さらに「キャラクターを削除するけど、線画だけは残してくれ」としてみたのが6枚目で、そこから「背景を夜にして、線画を光らせてくれ」としたのが1枚目、といった感じです。 nano bananaほど指示がきれいに反映されるというわけではなく、融通が利かないところもあるんですが、これをローカルのPCで使い放題というのは結構楽しいです。 いろいろ試してみたくなりますね。
 6
6
035:Anytestの使い方
全体公開
Wan2.2で動画を作るときにはポーズ差分の画像があるとStart-Endでフレーム指定で安定した動画が生成できるので、最近はポーズ差分画像をどう作るかをいろいろ試しています。 nano bananaは強力なのですが、制約があったり絵柄がnano banana絵柄に寄ったりするので他の手段も試している、というか。 私がメインで使っている画像生成モデルはAnimagine4なので、Controlnetでポーズ指定するという手が使えます。 SDXL系のControlnetとしてはAnytestという強力なブツがあるので、それを試してみました。 まずは2枚目のような、大雑把な構図指定画像を手描きします。これはClip Studio Paintでマウスでちょいちょいと5分程度で描いた代物で、「まあなんとなく言いたいことは分かる」レベルのものかな、と思います。 この構図指定画像を参照画像として設定しているのが3枚目の画像で、Anytestを使うためのComfyUIワークフローです。このワークフローで画像を生成したのが1枚目です。なんとなくそれっぽくはなっている気がしますね。 ↓プロンプトはこんな感じにしています。 1girl, _, from _, blonde long hair, blue eyes tareme, forehead, pointy ears large breast, groin tendon slim bod, single-shoulder long magical black robe, bra strap, mini skirt under robe frill skirt, contrapposto, water wave background, smile, (glitter magic circle effect:1.2) from hand, blue water effect, pure clear realistic water, splash water around wind blowing さて、Anytestですが、結構いろいろなことができる「万能Controlnet」と言われていて、例えば4枚目の画像の真ん中の部分を黒塗りでつぶして(5枚目)これを参照画像として渡すと、1枚目の画像のポーズを変更することができたりもします(6枚目)。 1枚目の画像と6枚目の画像を動画のStart-Endフレームに指定すれば、なんとなく水魔法を使っているエルフ姉さんの動画ができるような気がしますね! とまあこんな感じに便利なControlnet「Anytest」ですが、月須和さんがHuggingFaceで公開してくれています。ありがたいですね。 https://huggingface.co/2vXpSwA7
 3
3
034:InfiniteTalkで読み上げ動画を作る
全体公開
前回はWan2.2のS2Vモデルを使って、セリフ音声と画像から、読み上げ動画を作りましたが、今回はセリフ音声と動画から、読み上げ動画を作ってみます。 前回のはWan2.2 S2Vで1枚の画像から動画を生成したのですが、口元以外の箇所はあまり動かないというか、ほぼ口パク動画、みたいな感じでした。 今回は人物がなにか動いている動画をもとに、口元をセリフに合わせて口パクさせるというもので、動きのある読み上げ動画を作る場合はこちらの方が良いようです。 こういった手法はVideo to Video(V2V)と呼ばれているようですね。 読み上げのためのV2VにはInfiniteTalkを用いてみました。 InfiniteTalkはまだWan2.2には対応していないので、Wan2.1と組み合わせて使ってみています。 2枚目の画像がInfiniteTalkを使うためのComfyUIのワークフローで、画面下の方で元となる動画(1枚目)を指定しています。 セリフ音声は上の方(音声を読み込む、のところ)に指定してみています。 3枚目もワークフローの一部で、真ん中のあたりにプロンプトを指定しています。この手法の場合、キャラクターの見た目も動きも動画で指定しているので、プロンプトは簡単に「The woman turns to me, stretches her body, and speaks with a smile.」(その女性は私の方を向き、体を伸ばして、笑顔で話します)としました。 あとは実行すると、セリフ音声に合わせて口元の動きが調整されます。
 3
3
033:Wan22 S2Vで読み上げ動画を作る
全体公開
今回はWan2.2のS2Vモデルを使って、セリフ音声と画像から、読み上げ動画を作ってみました。 S2Vは、音声からそれに合った動画を生成するものですが、元画像を指定するとそれをもとにI2Vのように画像に沿った動画を生成してくれます。 前回使った魔法少女画像の顔アップ(2枚目)を元画像に指定し、音声として「魔法少女Muacca、いつもみんなと楽しく、ですです」という読み上げ音声を指定してできたのが1枚目の動画です。 残念ながらちちぷいには音声付の動画は投稿できないので、口パクだけになってしまいますが、元画像のキャラがなにかしゃべっている感じになっているのは分かるかと思います。 Wan2.2 S2Vですが、UIとしては公式から配布されているComfyUIワークフローを用いて実行しました(3枚目)。 基本的にはデフォルト値のままで使うのがいいようです。 ちなみに16fpsが指定されているのですが、これを30fpsとかにすると音声と口パクがズレるので、変えないほうが良いようです。fpsを変更したい場合は、生成した動画を別のツールでフレーム補間すればよいと思います。 あと、公式の情報では生成される動画は77フレーム分と書いてあって、これは変更しないほうが良いとのことでした。16fpsだと4秒くらいの動画になるはずなのですが、結果として生成されたのは14秒くらいのものだったので、それがなぜなのかはよくわかりません。投入した音声は4秒くらいだったので、ここに投稿しているものは後ろの無音声部分をカットしてあります。
他のクリエイターの投稿
 15
15
巨大インパクトハンマーガール
580コイン/月以上支援すると見ることができます
リンファ75
 9
9
戦うメイドさん
500コイン/月以上支援すると見ることができます
みそぴー

💝2月活動報告
全体公開
2月は🍫バレンタインや👹節分などの大型イベントがありました 運営さんも本格的(?)に活動始めたようでちちぷいちゃんが投稿イベントに参加するなど今年も色々ありそうな予感!? ユーザーも増えてるようで沢山のユーザーさんの画像が楽しめました°˖☆◝(⁰▿⁰)◜☆˖° ◆投稿企画(全年齢) ●コラボ企画#ゲーム攻略本(花笠さん) 開催期間:2026/2/20(金) 17:00~2026/3/1(日) 23:59 https://www.chichi-pui.com/events/collab-gamebook/ #ECHIDNA 開催期間:2026年1月30日17:00~2026年2月26日23:59 #節分 開催期間:2026年1月30日17:00~2026年2月3日23:59 #メイク 開催期間:2026年2月6日17:00~2026年2月10日23:59 #大正ロマン 開催期間:2026年2月20日17:00~2026年2月24日23:59 #魔法少女 開催期間:2026年2月27日17:00~2026年3月3日23:59 #DAISY 開催期間:2026年2月27日17:00~2026年3月26日23:59 ◆投稿企画(R18) #LUV 開催期間:2026年1月30日17:00~2026年2月26日23:59 #GHOST 開催期間:2026年2月13日17:00~2026年3月12日23:59 #自撮り 開催期間:2026年2月20日17:00~2026年2月24日23:59 #TUDE 開催期間:2026年2月27日17:00~2026年3月26日23:59 ◆期間限定モデルや追加モデル ■2月13日 GHOST(UL) ■2月25日 Seedream 5.0 ■2月27日 TUDE(UL) ■2月27日 DAISY ◆提供終了(おでかけ) ■2月13日 CLAK(UL) ■2月27日 PARAL(UL) ◇追加機能 ■2月18日 動画生成 ・Gemini Veo3.1 ・Seedance 1.0 Pro Fast ・Sora 2.0 (動画生成) 【2月のデータ】 投稿数 129 いいね!数 13,367 コメント数 175 ~アクティビティ~ いいね!した数 1,057 (上位7%) コメントした数 206 (上位6%) 集計期間: 2/1 〜 2/28 ※3/13からアクティビティなどが表示されるようになりました ●個人的なこと ★2026年2月16日 18万いいね達成しました いつもありがとうございます 2月もちち生モデル(全年齢)はすべて残留となりました 慣れてきたモデルも多く、こんなに沢山のモデルが使えるのは大変ありがたい事です (サーバー代とか気になってしまいます) 運営様ありがとうございます ★2026年第2弾ネームドキャラを作成しました 「ニーハイ」さん → マーチちゃん と、なりました 元々没キャラだったのですが沢山のイイネを頂けたのでこのまま使用していきます (彼女の代わりに用意していた無料キャラは封印となりました😅) 🌟今回の画像はBUTTERちゃんにGeminiさんで文字入れを行いました 🌟今年は運営さんのバレンタイン企画が無かったのでバレンタインBUTTERちゃんにご登場いただきました
ア ル
 6
6
華袴彩堂 壱
500コイン/月以上支援すると見ることができます
蜜華
 14
14
ちびめか騎士がーる
580コイン/月以上支援すると見ることができます
リンファ75
 7
7
レオタード少女236~242
100コイン/月以上支援すると見ることができます
まーるの別荘
 10
10
オーロラソード
580コイン/月以上支援すると見ることができます
リンファ75
 40
40
海
全体公開
sugasaは背景が欲しい
 16
16
シンギングガール
580コイン/月以上支援すると見ることができます
リンファ75
 7
7
草原少女01~07
100コイン/月以上支援すると見ることができます
まーるの別荘
 5
5
「瓶詰の少女」蒼56~60
100コイン/月以上支援すると見ることができます
まーるのおだんご工房🍡✨
 40
40
黒髪
100コイン/月以上支援すると見ることができます
sugasaは背景が欲しい
 5
5
AIで描く桜。空気感とディテールの両立について
100コイン/月以上支援すると見ることができます
ukkripp
 13
13
一日遅れのひな祭り
580コイン/月以上支援すると見ることができます
リンファ75
 40
40
緑髪
100コイン/月以上支援すると見ることができます
sugasaは背景が欲しい
 10
10
電脳世界樹
580コイン/月以上支援すると見ることができます
リンファ75